
1- بررسی معنی دار بودن مدل رگرسیون
برای آزمون این که آیا رابطه ی رگرسیونی ارائه شده بین متغیر پاسخ (وابسته) و متغیرهای پیشگو (مستقل) معنی دار است یا خیر با تعریف مدل رگرسیون به صورت،
![]()
فرضیه ی” ![]() ” را در برابر ” حداقل یکی از
” را در برابر ” حداقل یکی از ![]() ها مخالف صفر باشد” آزمون می کنیم .
ها مخالف صفر باشد” آزمون می کنیم .
با توجه به جدول تحلیل واریانس زیر آماره ی آزمون را معرفی می نماییم :
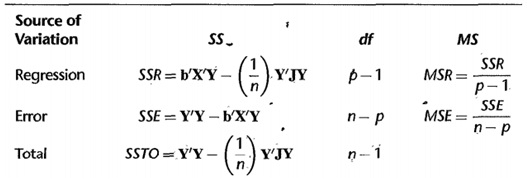
آماره ی آزمون
![]()
می باشد . ![]() با مقدار حاصل از جدول توزیع فیشر مقایسه می شود.
با مقدار حاصل از جدول توزیع فیشر مقایسه می شود.
اگر ![]() باشد، فرض صفر معنی داری مدل رگرسیون پذیرفته می شود. به عبارت دیگر با اطمینان
باشد، فرض صفر معنی داری مدل رگرسیون پذیرفته می شود. به عبارت دیگر با اطمینان ![]() درصد می توان گفت مدل ارائه شده توسط متغیرهای مستقل موجود به خوبی قادر به بیان تغییرات متغیر وابسته می باشد.
درصد می توان گفت مدل ارائه شده توسط متغیرهای مستقل موجود به خوبی قادر به بیان تغییرات متغیر وابسته می باشد.
اما در صورتی که ![]() فرض صفر رد می شود. یعنی مدل تعریف شده نمی تواند مدل مناسبی برای بیان تغییرات متغیر وابسته باشد.
فرض صفر رد می شود. یعنی مدل تعریف شده نمی تواند مدل مناسبی برای بیان تغییرات متغیر وابسته باشد.
مثال و خروجی رگرسیون در نرم افزار spss
به عنوان مثال فرض کنید می خواهیم رابطه ی فشارخون سیستولیک و وزن (![]() ) و سن (
) و سن (![]() ) را برای مردانی که تقریبا قد یکسانی دارند آزمون کنیم . نتایج حاصل و خروجی رگرسیون به کمک نرم افزار SPSS نسخه 22 به شرح زیر است :
) را برای مردانی که تقریبا قد یکسانی دارند آزمون کنیم . نتایج حاصل و خروجی رگرسیون به کمک نرم افزار SPSS نسخه 22 به شرح زیر است :
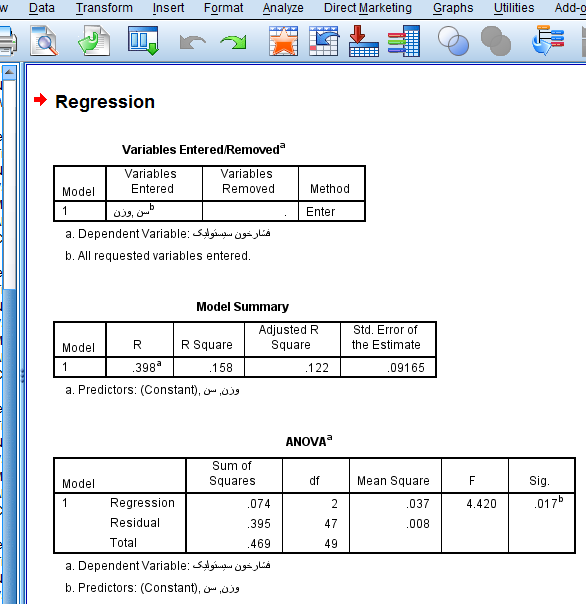
در ابتدای خروجی (اولین جدول) نرم افزار spss، به معرفی مدل می پردازد. اینکه متغیر وابسته چیست و متغیرهای مستقل (پیشگو) کدام هستند. همانطور که در خروجی مشخص است، متغیر وابسته “فشار خون سیستولیک” است و متغیرهای مستقل نیز “سن” و “وزن” هستند.
در دومین جدول خروجی نرم افزار اس پی اس اس برای تحلیل رگرسیون، ضریب تعیین و ضریب تعیین تعمیم یافته آمده است که نشان می دهد چند درصد از تغییرات در متغیر وابسته توسط متغیرهای مستقل و توسط این مدل رگرسیون تبییین شده است. در اینجا با استفاده از ضریب تعیین تعدیل شده می توان گفت 12.2 درصد از تغییرات متغیر وابسته توسط متغیرهای مستقل تبیین شده است، که نسبتا پایین است و بهتر است مدل مناسب تری در نظر گرفت.
اما سومین جدول در خروجی های spss مد نظر ما در این مبحث است که معنی داری کلی مدل رگرسیون را آزمون می کند. مقدار آماره ی آزمون معنی داری مدل که همان آماره F است برابر 4.420 است که با مقدار حاصل از جدول توزیع فیشر با p-1=3-1=2 و n-p=50-3=47 درجه ی آزادی مقایسه می شود (عدد 50 تعداد کل مشاهدات است). البته با توجه به p-مقدار آزمون که برابر 0.017 بوده و کمتر از 0.05 است فرض صفر با اطمینان 0.95% درصد رد می شود یعنی مدل موجود با اطمینان 0.95% درصد معنی دار بوده و بر اساس داده های موجود این مدل قادر به بیان تغییرات فشار خون سیستولیک می باشد.
2- آزمون ضرورت وجود هر یک از متغیرهای مستقل در مدل
به منظور بررسی ضرورت وجود هریک از متغیرهای مستقل در مدل یا به عبارت دیگر برای بررسی معنی داری ضرایب متغیرهای مستقل رگرسیون، فرضیه ی ![]() را در برابر
را در برابر ![]() آزمون می کنیم . آماره ی آزمون به صورت
آزمون می کنیم . آماره ی آزمون به صورت
![]()
تعریف می شود و در سطح ![]() با مقدار حاصل از جدول توزیع تی استودنت با n-p درجه ی آزادی مقایسه می شود.
با مقدار حاصل از جدول توزیع تی استودنت با n-p درجه ی آزادی مقایسه می شود.
چنانچه ![]() باشد، فرض صفر پذیرفته می شود یعنی ضرورتی برای وجود متغیر k ام در مدل وجود ندارد و احتمالا می توان این متغیر را از مدل حذف کرد. در صورتی که
باشد، فرض صفر پذیرفته می شود یعنی ضرورتی برای وجود متغیر k ام در مدل وجود ندارد و احتمالا می توان این متغیر را از مدل حذف کرد. در صورتی که ![]() باشد، فرض صفر رد شده و متغیر مستقل k ام در مدل باقی می ماند و دارای تاثیر معنی داری بر روی متغیر وابسته است.
باشد، فرض صفر رد شده و متغیر مستقل k ام در مدل باقی می ماند و دارای تاثیر معنی داری بر روی متغیر وابسته است.
مثال و تحلیل خروجی spss برای ضرایب رگرسیون
برای مثال فرض کنید می خواهیم رابطه ی فشارخون سیستولیک با وزن (![]() ) و سن (
) و سن (![]() ) را برای مردانی که تقریبا قد یکسانی دارند آزمون کنیم و در مورد لزوم وجود هریک از متغیرهای وزن و سن در مدل تصمیم گیری نمائیم. خروجی زیر توسط نرم افزار SPSS بدست آمده است (ادامه خروجی های نمایش داده شده در تصویر قبل):
) را برای مردانی که تقریبا قد یکسانی دارند آزمون کنیم و در مورد لزوم وجود هریک از متغیرهای وزن و سن در مدل تصمیم گیری نمائیم. خروجی زیر توسط نرم افزار SPSS بدست آمده است (ادامه خروجی های نمایش داده شده در تصویر قبل):
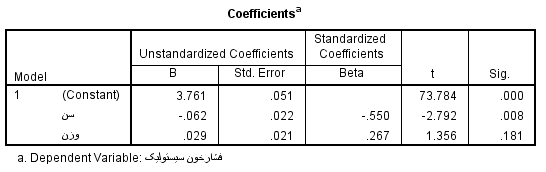
آماره ی آزمون مربوط به هریک از ![]() ها در ستون t value داده شده است .در سطح خطای 0.05% درصد هر یک از آن ها بایستی با
ها در ستون t value داده شده است .در سطح خطای 0.05% درصد هر یک از آن ها بایستی با
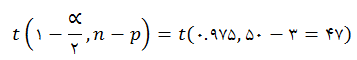
مقایسه شوند . علاوه بر آن به کمک p-مقدار و مقایسه ی آن با α=0.05 نیز می توان در مورد قبول یا رد فرض صفر تصمیم گیری نمود.
مدل حاصل از اطلاعات فشار خون ، سن و وزن 50 نفر به صورت
![]()
می باشد.
در این مثال p- مقدار (که نرم افزار spss آنرا با Sig نشان می دهد) مربوط به سن یا همان متغیر![]() کمتر از 0.05 می باشد و فرض صفر برای این متغیر رد می شود یعنی متغیر
کمتر از 0.05 می باشد و فرض صفر برای این متغیر رد می شود یعنی متغیر ![]() در مدل باقی می ماند. ولی با اطمینان 0.95 درصد می توان گفت ضرورتی برای وجود
در مدل باقی می ماند. ولی با اطمینان 0.95 درصد می توان گفت ضرورتی برای وجود ![]() در مدل وجود ندارد.
در مدل وجود ندارد.
منبع : کتاب مقدمه ای بر مدل های خطی آماری . نوشته ی مایکل کاتنر(Michael H.Kutner) و جان نتر (John Neter).
براي مشاهده ساير مقاله هاي تحليل آماري اين وب سايت بر لينک زير کليک نماييد: صفحه مقاله هاي تحليل آماري
38 دیدگاه. همین الان خارج شوید
با سلام خسته نباشید
از بابت اطلاعات مفیدی که در دسترس میذارید کمال تشکر رو دارم.
در پناه حق
سلام. خواهش، لطف دارید.
هر گونه پیشنهاد یا انتقاد شما بزرگواران را نیز پذیرا هستیم (در فرم صفحه “تماس با ما” ).
این منبعی که معرفی کردید چطوری میشه بهش دسترسی پیدا کرد؟؟
ممنون میشم راهنمایی کنید
این قبیل منابع در کتابخانه های دانشگاه ها قابل دسترسی است. احتمالا در کتاب فروشی ها نباشد
در جدول زیر داده های مربوط به اندازه شرکت ها به میلیارد تومان و نسبت P/E آنها داده شده است.
الف- معادله رگرسیون اندازه شرکت بر روی نسبتP/E را برآورد نمایید.
ب- از نظر آماری معنی دار بودن ضرایب برآورد شده رادر سطح معنی داری 5% آزمون کنید.
ج-ضریب تعیین مدل را محاسبه نمایید.
د-نتایج به دست آمده از محاسبات را تفسیرکنید. (نوع رابطه و میزان برازندگی)
1 2 3 4 5
7 10 4 11 6 اندازه شرکت
P/E 3 5 1 7 2 نسبت
با سلام و ادب محبت کنید مراحل ثبت در نرم افزار ایویوز و تحلیل را توضیح دهید .سپاسگزارم
سلام. به منو محصولات سایت ویژه نرم افزار ایویوز این شرکت بروید و محصول آموزش ویدئویی ورود داده را دریافت نمایید:
https://www.eviews-iran.ir/
با سلام، وقتتون بخیر
ببخشید من در مقالاتی که خوندم مثلا با (F(1,11)=19.002) رو برو میشم میخواستم بدونم عبارات هایی از این قبیل چه معنایی دارند و چطوری باید این چیزا مقاله ام را تحلیل کنم.ممنون میشم اگر راهنمایی ام کنید.
سلام. F(1,11)=19.002 یا مواردی مثل این مقدار آماره آزمون هستند (در اینجا مقدار آماره آزمون فیشر با درجات آزادی 1 و 11 است) که خدا وکیلی توضیح دادن آن برای فردی که تعداد واحد کمی آمار پاس کرده بسیار سخت است. شما همین قدر بدانید که این مقادیر را باید به کمک جداولی با مقدار بحرانی آن مقایسه کنید و در خصوص قبول یا رد فرضیه تصمیم بگیرید. اما نرم افزارهای آماری این مشکل را حل کردند و هر جا که آماره را گزارش می کنند کنارش sig را نیز گزارش می کنند که متقاضی فقط با مقایسه sig با عدد 0.05 تصمیم گیری کند که فرضیه رد یا قبول می شود.
با سلام،وقتتون بخیر
ببخشید میخواستم بدونم Hedges’ g=1.28 به چه معناست؟و چطوری باید ازش استفاده کرد؟ممنون میشم راهنمایی ام کنید.
سلام. متوجه نشدم مقداری که ارائه کردید متعلق به کدام خروجی نرم افزار است. نمیدانم.
سلام و عرض ادب
بنده نتایج حاصل از دو روش آزمایشگاهی را با استفاده از آزمون رگرسیون مورد بررسی قرار دادم، علیرغم وجود MEAN DIFFERENCE زیاد بین دو سری جواب، نتیجه رگرسیون خوب و قابل قبول بود. قابل ذکر است که میزان sLOPE معادله خیلی زیاد بود. کلا برای استفاده از رگرسیون یک خط، میزان slope و intercept قابل قبول چقدر است؟
از مطالب مفیدتون سپاسگزارم
سلام. در مبحث رگرسیون، ارزیابی بعد از اجرای مدل از نظر داشتن شرایط پایه ای و فروض اساسی رگرسیون خیلی مهم است. اگر اون فروض اساسی برقرار باشد نتایج رگرسیون قابل بررسی و تحلیل می باشد. برای اینکار معیار ما شیب خط رگرسیون یا معنی داری ضریب ثابت رگرسیون نیست. بلکه موارد زیر است:
ضریب تعیین، آماره دوربین واتسون برای عدم خودهمبستگی باقیمانده ها، نرمال بودن باقیمانده ها، عدم وجود همخطی، استقلال باقیمانده ها
بنابراین پاسخ شما بزرگوار، شاخص های نیکویی برازش رگرسیون است.
با سلام آیا ترفندی وجود دارد که بتوان با آن مسیرهایی که در تحلیل مسیر معنی دار نیستند معنی دار شوند
سلام. این سوال شما به مبحث “مدلسازی معادلات ساختاری و تحلیل مسیر” مربوط است که اطلاعات بیشتر در سایت های دیگر ما قرار دارد:
http://www.lisrel.ir
http://www.smartpls.ir
اما پاسخ: روشهای اصلاح مدل می توانند شما را به این نتیجه برسانند. حذف یک مسیر غیر معنی دار و ضعیف ممکن است باعث معنی دار شدن سایر مسیرهای غیر معنی دار گردد.
ممنون لطف و بزرگواری شما
سلام و عرض خسته نباشید. همان طور که میدونیم یکی از پیش فرض های تحلیل کواریانس، همگنی شیب خط هست، می خواستم بدونم چرا در بعضی موارد معنادار می شود؟ یعنی زیر 0/05 به دست می آید؟ و اگر زیر پنچ صدم بود چون پیش فرض تحلیل کواریانس رد شده، دیگر نمی توان از تحلیل کواریانس استفاده کرد؟ مرسی
سلام. بله پیش فرض ها باید برقرار باشد. اگر نباشه آزمون به درستی انتخاب نشده.
علت ناهمگنی: گروه ها در ابتدا همگن نبودن و یا پس از آزمون گروه کنترل هم تغییرات داشته
با سلام و تشکر
چرا در بعضی از آزمون های رگرسیون مقدار بتای استاندارد از یک بیشتر می شود؟ اگر بتا یک وبالاتر از یک بود آزمون دست است یا اشتباه و اگر درست می باشد تفسیرش چیست
با سپاس
سلام. خیر نتایج قابل استفاده نیست.
ضریب استاندارد مقداری بین صفر و یک هست.اگر بزرگتر از یک هست بیش برازشی اتفاق افتاده و بین متغیر مستقل و وابسته همبستگی قوی وجود داره.
سلام من دومتغییر وابسته و یک متغییر مستقل دارم آزمون نرمال بودن رو روی داد ها پیاده کردم و نرمال بودن حالا از چه تست T باید استفاده کنم؟
سلام. اگر دو متغیر وابسته دارید، شما آزمون های آماری رایج را نخواهید داشت. به نظر بایستی از مدل سازی معادلات ساختاری استفاده شود. سایت های ویژه معادلات ساختاری ما:
http://www.lisrel.ir – http://www.smartpls.ir
عرض سلام و ادب
جناب فرشجی ضمن تشکر از توضیحات و مقالات خوبتون من یک سوال دارم که اگر لطف کنید و راهنمایی بفرمایید بسیار ممنون میشوم.
ببینید در تحلیل مدل رگرسیون ضریب استاندارد شده بتا در جدول ضرایب اهمیت متغیر رو نشون میده و هر چی بزرگتر باشه اون متغیر اهمیت بیشتری در مدل ما داره اما یک جدول دیگه هم هست به اسم collinearity diagnostics (بررسی همخطی) که سهم متغیرها رو برای بیان پراکندگی متغیر وابسته مشخص می کنه حالا سوال من اینه: موقعی که ما توی تحلیل مون گزارش می کنیم که فلان درصد از تغییرات متغیر وابسته توسط متغیر فلان تبیین میشه، باید از کدام جدول استفاده کنم ضریب بتا رو برا تغییرات در نظر بگیرم یا مقادیر جدول بررسی همخطی؟ میشه فرقشون رو بگید؟
سلام و درود
پاسخ شما جدول ضرایب بتا است. جدول ضرائب همخطی، برای بررسی میزان هم خطی متغیرهای مستقل است و کنترل یکی از پیش فرضهای معتبر بودن رگرسیون (عدم وجود همخطی بالا). از جدول همخطی استفاده می شود برای اینکه اگر دیدیم دو متغیر همبستگی خیلی بالایی با هم دارند، یکی شان را حذف کنیم. این هم خطی برای اعتبار نتایج رگرسیون ضرر دارد. بایستی متغیرهایی در سمت راست معادله رگرسیون باشند که خودشان خیلی با هم همبسته نباشند.
باسلام دانشجوی ارشد رشته تغذیه دام هستم
استادم مسئله ای درخصوص حل مسئله ای درخصوص جوجه گوشتی رگرسیون درنرم افزار spss خواستند میتونید کمکم کنید
سلام. موضوع داده ها و تحقیق برای نرم افزار SPSS تفاوت نمی کند. داده های مرتبط با مساله خود را جمع آوری نمایید و آنگاه با استفاده از نرم افزار آزمون رگرسیون را انجام داده و نتایج را تجزیه و تحلیل کنید. آمار علم تصمیم گیری است.
با سلام و عرض ادب
میشه همبستگی بین دو متغیر معنادار نباشد ولی اثر گذار بر روی هم باشند و در تحلیل مدل اثر مستقیم و غیر مستقیم آن معنادار بدست آید؟
ممنون از پاسخگویی شما
سلام
بله چون در رگرسیون ضرایب همبستگی در حضور سایر متغیرها حساب میشن. برعکس هم امکان پذیر هست
سلام متشكرم از مطالب مفيدتون
ببخشيد من موضوعم رابطه اي هست و ميخواستم اثبات كنم كه اين ٣تا متغيرم رابطه معنادار دارند براي همينم از پيرسون استفاده كردم اما تمام اعدادم منفي شدن و فرضيه هام رد ميشن و هيچ رابطه معناداري بينشون نيست .به من گفتن اعداد رو تغيير بده اما بي فايده بود لطفا كمكم كنيد😔ممنونم
سلام. ضریب همبستگی می تواند منفی اما معنی دار باشد. یعنی دو متغیر به صورت معنی داری بر روی یکدیگر اثر معکوس دارند.
بهرحال اگر فرضیه ها رد می شود، تنها کاری که می شود کرد این است که متغیرها را از نظر وجود داده های پرت یا اشتباهات تایپی حین ورود داده بررسی کنید. ترسیم نمودار هیستوگرام کمک زیادی می کند به اینکه به نوع رابطه دو متغیر پی ببرید.
سلام خسته نباشیدسوال 2:
در مطالعهای که به منظور بررسی میزان تاثیر متغیرهای تاثیرگذار بر دریافت یارانه معیشتی در سطح خانوارها انجام شده است پس از برآورد الگوی لاجیت محقق متوجه شده است که اکثر متغیرها به لحاظ آماری بیمعنی شدهاند. اگر این محقق تصریح مدل را به لحاظ متغیرها و فرم تابعی درست انجام داده باشد و خطایی از این بعد نداشته باشد، به نظر شما چرا اکثر متغیرها بیمعنی شدهاند؟ پیام سیاستی این رفتار در متغیرها به قانونگذار و یا قوه مجریه چه میباشد؟ آیا در تخصیص یارانه معیشتی درست عمل شده است یا خیر؟ اگر خطایی وجود دارد فکر میکنید این خطا از چه ناحیهای است؟ توجه داشته باشید که ضریب تعیین این مدل نیز بسیار پایین شده است یعنی در حدود 0.08
سلام. با توجه به ضریب تعیینی که ذکر کردید یعنی حدود 0.08 ، ابتدا ببینید که آماره اف معنی دار هست یا خیر؟ اگر این آماره معنی دار نباشد که باید گفت در کل مدل معنی دار نیست و لذا هیچ ارتباطی بین متغیرها قابل تایید نیست.
بهرحال این سطح بسیار پایین ضریب تعیین مشکل اصلی این برآورد مدل است و آنرا فاقد ارزش می سازد.
در خصوص تحلیل نتایج، باید عرض کنم که این قبیل تحلیل ها را فقط افرادی می توانند بنویسند که کسب و کار و موضوع تحقیق را کاملا می شناسند و خبره هستند و تحلیل گر آماری نمی تواند چنین توضیحاتی را بیان کند.
با سلام ممنون میشم سوال من رو پاسخ بدید:
روشی که نرم افزار SPSS برای آنالیز حساسیت استفاده میکند جزو روشهای RSA یا گلوبال است که همزمان متغیرها را تغییر میدهد و یا روش LOCAL یا ONE AT A TIME میباشد که در هر ران فقط یک پارامتر تغییر میکند؟
سلام ممنون از مطالب آموزشی
درصد تاثیرگذاری هر یک از متغیر های مستقل چگونه مشخص میشه؟
سلام وقتتون بخیر من پنج تا متغییر داشتم کامپیوت گرفتم می تونم رگرسیون انجام بدم؟
سلام. اگر الان 5 متغیر کامپیوت گرفته شده دارید، بله می توانید رگرسیون انجام دهید. منتها کنترل کنید که فروض رگرسیون در نهایت برقرار باشد، مثلا باقی مانده ها دارای توزیع نرمال باشند.
سلام. در رگرسیون، اگر به ضرایب استاندارد مراجعه نمایید، درصد تاثیر گذاری را در آنها می توانید ببینید.
سلام وسپاس بابت محبت شما….
یک کتاب مناسب برای مطالعه وفهمیدن دقیق ازمونها وهمبستگی و رگرسیون وامارپیشرفته جهت طرح ازمایشات بمن معرفی فرمایید.
سلام. کتابها مرتب در حال تغییر هستند. کتابی که امروز در کتاب فروشی است، سال آینده نیست و کتابهای جدیدی آمده اند. آزمون های آماری ده ها سال است که تغییر نکرده اند. شما یک کتاب با محوریت طرح آزمایشات که در یک کتاب فروشی معتبر بیابید و مطالعه کنید، انشاءالله به هدف مد نظر خود خواهید رسید.
نکته مهم این است که همزمان کار با نرم افزار spss را هم انجام دهید. به نظر من اگر برای یک روش اماری، کار با نرم افزار آنرا یاد گرفتید، می توان گفت که آنرا آموخته اید. بالاترین مرحله یادگیری جایی است که با نرم افزار کار کرده، خروجی بگیرید و نتایج را تحلیل نمایید. ویدئوهای آموزش spss این سایت ما را تهیه نمایید:
https://www.spss-iran.com/