
1- مقدمه
یکی از اساسی ترین سوالات در یک تحقیق، مقایسه ی میانگین یک شاخص دردو یا چند گروه می باشد.
برای مثال مقایسه ی نتایج درمان به کمک یک داروی خاص در دو گروه زنان و مردان که مقایسه میانگین ها دردو گروه بوده و با استفاده از آزمون t قابل اجرا است ویا مقایسه ی میانگین یک شاخص در بیش از دو گروه مانند مقایسه نتایج درمان در سه گروه از بیماران که از سه داروی مختلف استفاده می کنند ،گروه اول از پلاسبو (دارونما) ، گروه دوم ازداروی ضدافسردگی سه حلقه ای و گروه سوم گروهی است که یک مهارکننده ی اختصاصی بازجذب سروتین (SSRI) دریافت می کنند . در این حالت ، مقایسه میانگین گروه های مختلف توسط روش آماری تحلیل واریانس (ANOVA) انجام می شود .
پس از تعیین وجود یا عدم وجود اختلاف بین گروه های آزمون (بررسی معنی داری آزمون در جدول آنالیز واریانس)، این سوال مطرح می شود که تفاوت میانگین بین کدام دوگروه معنی دار می باشد؟ در همین راستا روش های متنوعی برای مقایسه ی میانگین بین گروه ها وجود دارد که عبارتند از آزمون حداقل تفاوت معنی دار(LSD) ، آزمون دانکن ، آزمون توکی، آزمون دانت و آزمون نیومن کولز .
در این صفحه به معرفی و تبیین خروجی نرم افزار spss برای آزمون توکی می پردازیم.
2- آزمون توکی
توکی (1953) یک روش مقایسه چندگانه را بر مبنای آماره ی دامنه استیودنت پیشنهاد کرد. در روش وی از
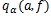
برای تعیین مقدار بحرانی تمام مقایسه های جفت میانگین ها استفاده می شود . بنابراین آزمون توکی در صورتی دو میانگین را دارای تفاوت معنی دار اعلام می کند که قدر مطلق اختلاف نمونه ی آن ها بیش از
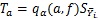
باشد.
3- خروجی spss از آزمون تعقیبی توکی
خروجی در نرم افزار اس پی اس اس به قرار زیر است.
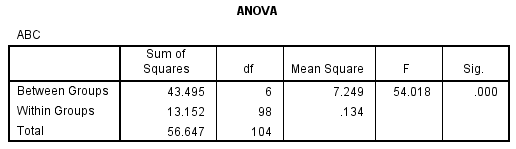
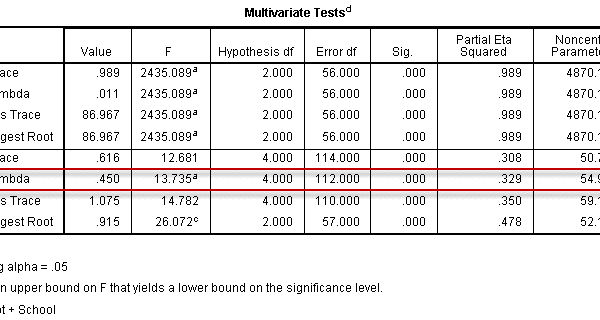
جدول آنالیز واریانس برای تشخیص معنی داری کلی مدل:
خروجی آزمون توکی HSD:
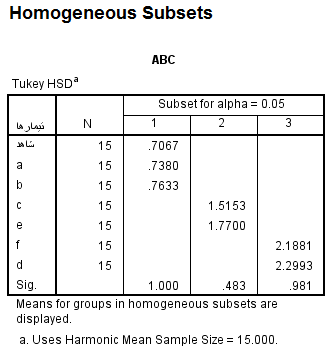
همانگونه که ملاحظه می شود این آزمون تعقیبی گروه ها (تیمارها) را به سه دسته تقسیم بندی کرده است. در داخل دسته ها تیمارها تفاوت معنی داری با هم ندارند اما میانگین تیمارهای بین دسته ها تفاوت معنی داری با هم دارند.
4- کدام آزمون تعقیبی (Post Hoc) ارجحیت دارد؟
اغلب تصمیم گیری در مورد این که کدامیک از آزمون های معرفی شده ارجحیت دارد ، کار دشواری است و بسته به نظر تحلیلگر آماری مربوطه دارد.
لیکن کارمر و اسوانسن در مطالعه ای که در مورد تعدادی از روشهای مقایسه ای چندگانه انجام دادند اعلام کردند که روش حداقل اختلاف معنی دار روش بسیار مؤثری برای نشان دادن اختلاف های واقعی میانگین ها می باشد مشروط بر این که تنها پس از معنی دار بودن آزمون f تجزیه واریانس استفاده شود. آن ها همچنین قابلیت شناسایی مناسب تفاوت های واقعی را با استفاده از آزمون چند دامنه ای دانکن گزارش کردند.
منبع :خلاصه ای بر طرح و تجزیه آزمایش ها . نوشته داگلاس سی . مونت گومری ترجمه محمدرضا دهقانی نشر پلک

22 دیدگاه. همین الان خارج شوید
سلام خداقوت
خیلی مفید وقابل فهم بود.ممنون از اینکه درارائه دانش سخاوتمندانه برخورد می کنید.موفق باشید
سلام. بزرگوارید
سلام
وقتتون بخیر
توی پژوهشی که دارم انجام میدم وقتی از آزمون رگرسیون برای بررسی رابطه متغیر وابستم و شاخصا به دلیل نرمال نبودن شاخصا به جواب نمیرسم، ولی وقتی میانگین شاخصا رو حساب میکنم و متغیرای مستقلمو تعریف میکنم رگرسیون جواب میده، از تمام روشای نرمال سازی (به جز روش جانسون که دستورشو تو spss پیدا نکردم) برای نرمال سازی داده هام استفاده میکنم ولی متاسفانه نرمال نمیشن، ممنون میشم راهنمایی بفرمایید
سلام و روز بخیر. توجه داشته باشید که در رگرسیون نرمال بودن متغیرها ملاک عمل نیست، بلکه آنچه ضروری است نرمال بودن باقیمانده های مدل است. پس روی آن و با توجه به آن کار کنید.
اگر باقیمانده های مدل نرمال نبودند، متغیرها را بررسی کنید که داده پرت نداشته باشند و اگر داده پرت وجود داشت آنرا حذف کنید. شناسایی داده های پرت از طریق ترسیم نمودار هر متغیر در اکسل قابل انجام است.
منظور از باقی مانده ها در رگرسیون چیست؟
باقیمانده ها که به آن جملات خطا یا اخلال نیز گفته می شود، تفاوت بین مقادیر برآورد شده در مدل رگرسیون و داده های واقعی در متغیر وابسته هستند.
در همین سایت در خصوص رگرسیون مباحث خوبی شده است. به آنها مراجعه داشته باشید. می توانید از بخش جستجوی سایت استفاده کنید.
سلام.برای مقایسه میانگین سنی زن ومرد درشهرهای مختلف درصورتی که متغیرشهر دارای ۶گروه باشد میتونیم ازanovaاستفاده کنیم؟
سلام. بله
سلام من چند نمونه از چند تیمار (چند گونه گیاهی)برداشت کردم میخواستم با منطقه شاهد مقایسه کنم از کدام آزمون وچکار کنم
سلام. از روش آنالیز واریانس استفاده و هر کدام از این آزمون های مقایسات میانگین را می توانید استفاده کنید از جمله همین آزمون توکی را. آزمون دانکن معروفیت بیشتری دارد.
سلام
در مثالی که از آزمون تعقیبی آوردید اگه در ستون شماره یک داده های a,b,c و در ستون شماره دو داده ها b,c,d وجود داشته باشد یا عبارت دیگر ، مقدایر b , c در هر دو ستون ا و 2 استفاده شده باشد . آن وقت نتیجه را چطور باید تفسیر کرد
سلام. قاعدتا چنین پاسخی توسط نرم افزار صادر نخواهد شد. چون مغایرت دارد با تفکیک بین دسته ها.
توجه کنید که اگر نتیجه آنالیز واریانس معنی دار باشد آنوقت می توانیدبه سراغ این آزمونها بروید.
با سلام و عرض خسته نباشید
اگر آزمون تعقیبی دانکن و LSD نتایج یکسان ارائه دهند ولی آزمون شفه نتایج دیگری نشان دهد . کدام نتیجه را باید قبول کرد ؟
در ضمن تعداد نمونه ها کم است و واریانس بین گروه ها برابر
سلام. سوال سخت و ظریفی است. لازم است در منابع و کتابهای آماری و spss به تفاوت های جزئی بین شرایط اجرای آزمونها مراجعه کنید. الان حضور ذهن ندارم.
سلام چطور میتونیم با شما ارتباط داشته باشیم؟
سلام. از طریق پیام رسان ها بهترین روش ارتباط با ماست. زیرا می توانیم بعد از بررسی فایلهای ارسالی شما در خصوص سوال یا کار شما اظهار نظر داشته باشیم. شماره واتساپ در پایین صفحات سایت درج شده است.
سلام وقتتون بخیر.ممکنه چند کتاب معرفی کنید که آزمون های تعقیبی رو به طور مفصل توضیح داده باشند.ممنون
سلام. کتاب طرحهای آزمایشی در کشاورزی ولی زاده و مقدم.
سلام وقت شما بخیر من در حوزه شیمی تجزیه کار میکنم میخوام سه تا ماده رو با هم مقایسه کنم و یکیشون رو انتخاب کنم برای انتخاب ماده میخوام از روش F -test استفاده کنم داده هام رو چه طور به دست بیارم یعنی باید آزمایش رو برای هرکدومشون چندبار تکرار کنم و بعد استفاده کنم یا اینکه روش دیگه ای هست؟
سلام. یک طرح آزمایش مناسب بایستی طراحی کنید و داده ها را جمع آوری نمایید. سپس از روش آنالیز واریانس یا همان اف تست استفاده کنید. طرح ریزی آزمایش به گونه ای که تغییرات را نمایان کند، اهمیت زیادی دارد. با استاد مشورت کنید و از مقالات معتبر به عنوان بیس استفاده نمایید. تکرار آزمایش هم لازم است
با سلام و احترام
من نتایج چند داروی مختلف را بر روی زخم تعدادی موش بررسی کردم آزمون توکی اعداد با اختلاف بالا را معنی دار نشان میدهد مثلا برای زخم با اندازه میانگین گروه 8 و 8.78 تفاوت معنی داری قائل نمیشود آیا آزمونی وجود دارد که حداقل تفاوت معنی داری را نشان دهد؟چرا در آزمون توکی چنین اتفاقی می افتد؟
سلام. سایر آزمون های مقایسات میانگین را نیز انجام دهید و نتایج را بررسی و مقایسه کنید. مثل دانکن، دانت، نیومن کولز …